Filtering LinkedIn Job Alerts with Serverless Python.
How I built myself a service that filters LinkedIn job alerts by description language.
I’m currently living in the Netherlands and looking for work. Rather pathetically, I don’t speak Dutch. (I should have said “I don’t yet speak Dutch” — there’s always hope, right?) Undeterred, I’ve set up email alerts for local jobs on LinkedIn. About a third of the alerts are for jobs that have descriptions written in English while the rest are in Dutch. My working assumption is that if the job description is in English then there’s a chance that they’ll speak English in the office and it’s worth finding out about it.
One problem is that I can’t immediately find a way to filter the jobs I receive by the language of the job description¹. Often job titles are in English but the descriptions are in Dutch. I imagine this is a non-problem for most Dutch people given that their English is excellent. But, for me, the process of clicking through all the email links can be frustrating. I’d to be able to filter the job alerts based on the language of the description. For now, it would be good enough if I could forward the emails to somewhere and have a filtered list sent back.
This post describes a solution I cobbled together along those lines over a weekend. In doing so I learnt how to use Amazon’s SES and Lambda services. I also discovered a few useful Python packages that I hadn’t heard of before. There were a few mis-steps along the way and I hope by writing about them you will be able to avoid them (at the expense of long-windedness).
I broke the job down into 4 tasks: * Work out how to extract the job description URLs from the job alert email sent by LinkedIn. * Get hold of the full job description and decide what language it is in. * Construct an email containing a (filtered) list of jobs. * Find out how to receive an email, do work on the content, and send it back.
I started by tackling the most familiar tasks. You may be most interested in the part about linking AWS services together. In this case, skip to task 4.
Task 1: Work out how to parse an email, extract the urls of each job, and fetch the job descriptions.
I actually knew very little about emails other that you can request them in plain text sometimes. The emails I get from LinkedIn look like HTML. It turns out, of course, that there’s a venerable standard format for email.
Using the ‘Show Original’ option from within GMail you can see or download the ‘raw’ email message in this format.
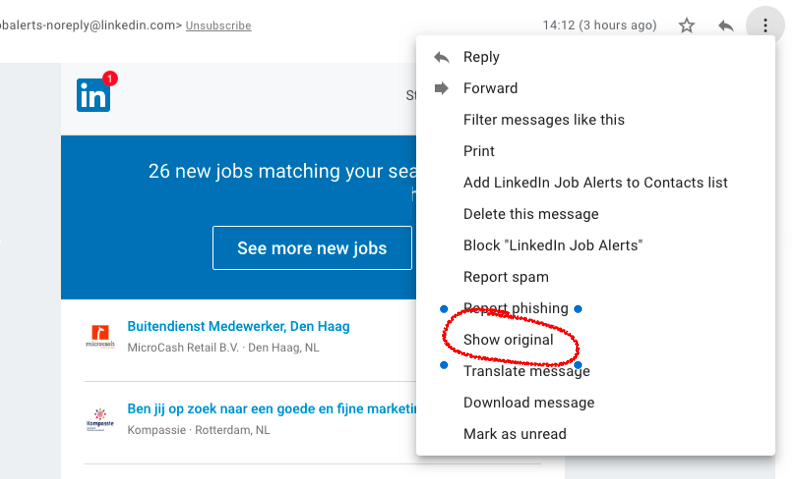
Using GMail’s ‘Show Original’ command to see the actual email as received.
The email from LinkedIn is a multipart MIME message with two parts. Each part contains a list of jobs, first in plain text and then again in HTML. Each list contains the URL of the full job description on LinkedIn. It’s these URLs I want to extract from the email using Python. I soon discovered that the Python standard library has a package called email. Loading an example email with this package gives me two Message objects with content types ['text/plain', 'text/html']:
import email
with open('sample_email.eml','r') as f:
e = email.message_from_file(f).get_payload()
print([ms.get_content_type() for ms in e])At first I thought it would be more robust to parse the HTML part with a library like lxml. But what a mess it was! To make their emails p̵r̵e̵t̵t̵y̵ / on-brand, email marketers have to embed all their CSS inline. This seems to be to the detriment of semantic meaning.
Instead, I wrote a hacky snippet to extract URLs and other details from the plain text:
def extract_jobs(plain_text_body):
"""
Extract the title, company, location and job ids contained in message body
"""
job_ids = [j.split('?')[0] for j in plain_text_body.split(f'View job: {LI_BASE_URL}')[1:]]
job_meta = plain_text_body.split(f'View job: {LI_BASE_URL}')[0].split('\n')[-4:-1]
jobs = [j[0] + (j[1],) for j in zip(job_meta,job_ids)]
return jobs
An update from the near-future: In fact this wasn’t very robust at all and not because LinkedIn changed the message format. It works fine on the example email I had downloaded from GMail. But after I got everything linked together and tested it for real I received no jobs at all! It turns out that when you forward an email, GMail doesn’t send on that same original version that you see when you ‘Show Original’. Instead it sends a pre-processed version and this doesn’t preserve the formatting of the plain text part.
I re-did the parser using regular expressions to find the job urls. This was probably a better approach all along:
import re
LI_BASE_URL='https://www.linkedin.com/comm/jobs/view/'
# extract matching urls from the plain text of email message
urls = re.findall(LI_BASE_URL+r”\d+”, plain_text_body)
# extract the id numbers from the found urls
job_ids = set([x.split(‘/’)[-1] for x in urls])Task 2. Get hold of the full job description and decide what language it is in.
Fetching the job description. Armed with a list of job ids I can fetch the job description for each one and determine if it’s in English or not. I used two packages to do this: requests , langdetect, and html from the standard library.
Requests lets us fetch the job description from LinkedIn:
import requests
# assume job_id is from above e.g. 1691926414
BASE_URL = 'https://www.linkedin.com/comm/jobs/view/'
r = requests.get(f'{BASE_URL}{job_id}')As I wanted to keep the number of third-party libraries down I wrote a custom HTML parser using the Python standard library html.parser. This runs over the job description page and extracts the description and other meta data such as the job title, company, and location.
class DescriptionParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.recording_title = False
self.recording_desc = False
self.data = {'title':'','description':[]}
def handle_starttag(self, tag, attributes):
if tag == 'title':
self.recording_title = True
elif tag=='div':
for name, value in attributes:
if name == 'class' and value == 'description__text description__text--rich':
self.recording_desc = True
else:
return
def handle_endtag(self, tag):
# we only go one deep
if tag=='div':
self.recording_desc = False
if tag=='title':
self.recording_title = False
return
def handle_data(self, data):
if self.recording_title:
self.data['title']=data
print('title:',data)
if self.recording_desc:
self.data['description'].append(data)The parser is invoked on the HTML response as follows:
# create instance of parser
dp=DescriptionParser()
# feed it the HMTL from the email
dp.feed(r.text)
# access captured data from the parser instance
# e.g.
title = dp.data.get('title','No Title Found')
place = title.split(' in ')[1].split(' | ')[0]
job_title = title.split(' hiring ')[1].split(' in ')[0]
company = title.split(' hiring')[0]Detecting the language of the description.
I was about to go and make a call to 0800-Google Translate-API when I came across the awesome python package langdetect. It apparently supports 55 languages out of the box. We can simply feed the text of the job description to the detect function and it will return the detected language.
from langdetect import detect
language = detect(dp.data['description'])The job descriptions I receive are a mix of Dutch and English. I ran an unscientific test of the performance of langdetect by passing in a handful of example descriptions. It seemed to get it right all of the time. As nobody’s life is on the line here that’s good enough for me.
So now all I need to do is wrap those last 3 parts into a loop that creates a list of only the jobs that have English descriptions. I hope this snippet is fairly self-explanatory:
def filter_jobs(job_ids, required_languages=['en']):
"""
Filter the list of jobs to keep only those where job description is in the list of required languages.
"""
filtered_jobs = []
for job_id in job_ids:
job_url = f'{LI_BASE_URL}{job_id}'
r = requests.get(job_url)
if r.ok:
dp=DescriptionParser()
dp.feed(r.text)
title = dp.data.get('title','No Title Found')
place = title.split(' in ')[1].split(' | ')[0]
job_title = title.split(' hiring ')[1].split(' in ')[0]
company = title.split(' hiring')[0]
try:
language = detect('\n'.join(dp.data['description']))
except:
language = 'unknown'
if language in required_languages:
filtered_jobs += [(job_title,company,place, job_url)]
else:
# better luck next time, no retries
continue
return filtered_jobsTask 3. Construct an email of the filtered jobs to send back to myself.
Now that I have the filtered job listings I need to construct an email to send back to myself. Let’s go for a MIME Multipart message in plaintext and HTML, like the one I received from LinkedIn. There were two parts to this task: building the plaintext and HTML message parts, and then wrapping these in a standard format email.
The plaintext part was very simple. I concatenated the meta data and URLs of each job together as a string.
To make the HTML part I found the helpful dominate package. After a few iterations, I decided to put the job list in a <table> element. I also feel I’ve given back to the email marketing community by including some inline css. ;-)
This snippet shows a function to build these parts of the reply:
def build_reply(filtered_jobs,subject):
# build a message in plain text and html to send back
datefmt = datetime.now().strftime("%d %B %Y")
salutation=f'These are your filtered job alerts for {datefmt}'
plaintext_body = f'Job Alerts\n-------------\n{salutation}\n\n'
plaintext_body += '\r\n'.join([f"{i+1}. {', '.join(j)}" for i,j in enumerate(filtered_jobs)])
plaintext_body += '\nThanks for using li-filter'
htmldoc = dominate.document(title='Job Alerts')
htmldoc.add(body()).add(div(id='content'))
# put the jobs in a table with links.
clrs=['#ffffff','#EEF7FA']
with htmldoc.body:
h1('Job Alerts')
p(subject+f" on {datefmt}")
head_style = "background-color:#005b96;color:#ffffff;border:0;font-weight:bold"
cell_style = f"border:0;padding:0.25em"
with table(style='border-collapse: collapse;').add(thead([td('',style=head_style),
td('Job Title',style=head_style),
td('Company',style=head_style),
td('Place',style=head_style),
td('Id',style=head_style)])).add(tbody()):
for i,job in enumerate(filtered_jobs):
row_style = f"background-color:{clrs[i%2]};border:0"
trow = tr(style=row_style)
trow += td(f'{i+1}.',style=cell_style)
trow += td(job[0],style=cell_style)
trow += td(job[1],style=cell_style)
trow += td(job[2],style=cell_style)
trow += td(a(job[3].split('/')[-1],href=job[3]),style=cell_style)
return (plaintext_body, htmldoc)My first attempt to wrap these messages into an email used the email package from the standard library. It was quite straightforward to follow the examples in the documentation. But I ended up stripping that code out and using the boto3 API for creating and sending emails instead. We look at that part next.
Task 4: Find out how to receive an email work on the contents and send one back.
At the start of this post I described my general plan. This was to forward the job alert email to some python process for filtering. To enact this plan I need to be able to receive emails and feed the content of the emails into the filtering code.
I understand that people run their own email servers and I assume there are some python packages to do that. But it seems a waste to be running a server when I only receive the job emails infrequently. Instead it sounded like a good use case for a serverless approach. I’d like to have a function ‘wake up’, filter an email, and then power-down again.
AWS’s Lambda seemed a reasonable place to start². But I’ll still need a way to trigger a Lambda function on receipt of an email. Sure enough, AWS have a service for that. It’s called the Simple Email Service (SES).
“When you use Amazon SES to receive messages, you can configure Amazon SES to call your Lambda function when messages arrive.” — AWS Documentation
Perfect! I started reading around creating Lambda functions and using SES, following the Receiving Email Getting Started Guide. There are few admin steps to get through with SES. First, you have to verify that you own the domain you want to send emails from. Also all new SES accounts start off in a sandbox. This means you can only send emails to an address you have verified. For this project these restrictions don’t matter. I only want to send and receive from one email address, which is my own.
One of the main concepts of SES is receipt rule sets. Receipt rules specify what Amazon SES should do with mail it receives. To get SES to call a Lambda when it received an email, I started following the official documentation. I had imagined that the content of the email would pass to the Lambda. I soon found out that the body of the incoming email is omitted.
To get the content of the email in a Lambda function we must configure SES to put a copy of the email into an S3 bucket. The Lambda can then fetch the email from S3 using the information provided from SES. I worried that this was becoming complicated.
It was with relief then that I came across this example by Dincer Kavraal, which became the backbone of my solution. The parts about setting up Roles are important to get right and it took me a little to get familiar with that. If you step through it carefully yourself it should work. As a result I was able to set up SES and Lambda to receive emails and bounce back a reply.
Shoehorning the filtering code into a Lambda.
So we have a working harness for receiving and sending emails. Now I need to get my email filtering code into that framework. Up to this point I had been editing (or, more accurately, copy/pasting) code directly in the Lambda console. It worked well but I knew that my filtering code relied some extra python packages. I would somehow have to bundle these up and push them to the Lambda. And I was a bit lost about that at first.
This is where I found another great help in the form of the python-lambda package. I followed these guidelines to install it and set up a new local folder. Then from a fresh pipenv shell I called lambda init to create the following files:

The directory structure created by python-lamda
Inside service.py is the all important handler() function that is invoked whenever the Lambda is called.
So, first I copied Karvaal’s example code into the handler function. Then I could graft in parts of my own email filtering scripts.
The main adaptations to my code were on the plumbing:
* Use the content fetched from S3 rather than reading an email from a file
* Use the boto3 API to package up and send an email rather than the standard python email package.
The full code is available on Github.
The beauty of python-lambda is that after setting up the config.yaml file I could simply deploy this code to AWS. Either directly (lambda deploy), via S3 (lambda deploy-s3) or creating a zip to be uploaded by hand (lambda build). On choosing one of these options python-lambda bundles up all of the source code and packages into a zip file. The build option makes this a little more transparent because it creates a directory called dist/ and puts the zip file in there. I was pleasantly surprised at how easy this made it.
Task 5. Forward some alert emails to SES.
So with code bundled and deployed I was ready to forward emails to my new service. How exciting! But then… how disappointing! At first I received no job alerts back. The main parts of the machinery seemed to be working. My forwarded email was received and a reply sent back. It just didn’t have any jobs in it.
This was the gotcha I described earlier where by Gmail doesn’t forward the raw email that we looked at originally and instead sends a pre-processing version. I tweaked the email parser using regular expressions and tried again. This time it worked and it was quite satisfying to see.
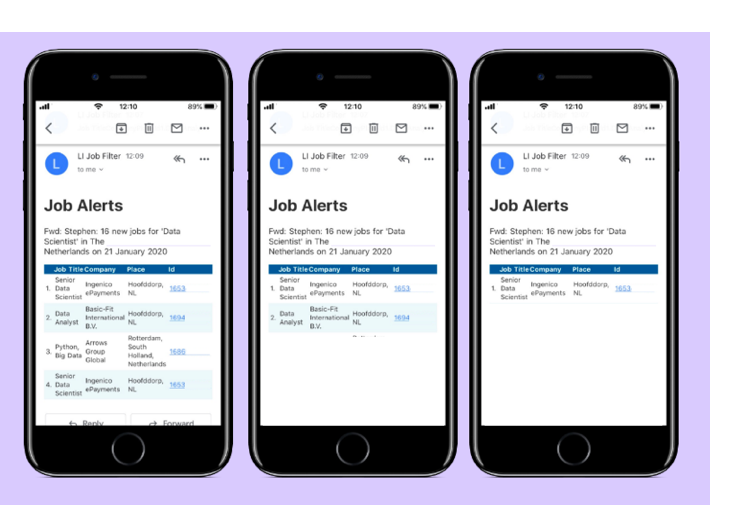
Job alerts filtered by the language of the description in my inbox.
Task 6. Bask in glory.

There was probably an easier way!
Using the examples of others I was able to pull this together in a relatively short time. Given I hadn’t used SES or Lambda before I was surprised how easy it seemed. I have to admit that it was not entirely without headaches though. I found configuring permissions for AWS services to talk to each other got a bit tricky. And sometimes the AWS documentation feels like it’s driving you in circles. Thanks to Dincer Kavraal and Todd Birchard for their examples that got me on my way.
Already the basic framework for receive, trigger filter, send created here has come in useful on another side project.
Notes
[1] Yes, I’m waiting for it to be pointed out how obvious it is to filter by language, but I wanted a side project. [2] I’m not advocating AWS over Google Cloud or Microsoft Azure, I just looked there first and found what I wanted.